Tesseract简介
tesseract是一个图像识别库,底层是用C++写的,tesseract支持unicode编码,能够识别100多种语言;
Tesseract支持各种输出格式:纯文本,特殊(html),pdf,tsv,仅隐形文本pdf
- tesseract历史:
Tesseract最初是在1985年至1994年间在Hewlett-Packard Laboratories Bristol和Greeley Colorado的Hewlett-Packard Co开发的,1996年又进行了一些更改以移植到Windows,并在1998年开始使用一些C ++。2005年,Tesseract开放了 惠普采购。 自2006年以来,它由谷歌开发。 - 版本:
最新的稳定版本是3.05.01,于2017年6月1日发布。最新的3.05源代码可从GitHub上的3.05分支获得。
新的基于LSTM的4.0版本的源代码可从GitHub上的主分支获得。 请注意,该分支正在积极开发中。
tesseract官网地址 - tesseract可以用来识别图像和验证码,自带的命令可以识别数字字母等,准确率很高,需要中文和其他语言可以自行下载相关的语言库,如果想要再次提高准确率可以抽取足够多的样本,然后自己训练,本人做的电话号码和邮箱的识别库准确率可以接近99%;
安装
1 | mac brew install |
- 当然也可以直接到代码库里面直接下载语言库:语言库网址, 下载*.traineddata文件放到本地语言库目录,mac下是:/usr/local/share/tessdata,ubuntu下是:/usr/share/tesseract-ocr/4.00/tessdata/
运行
安装成功以后执行tesseract如下图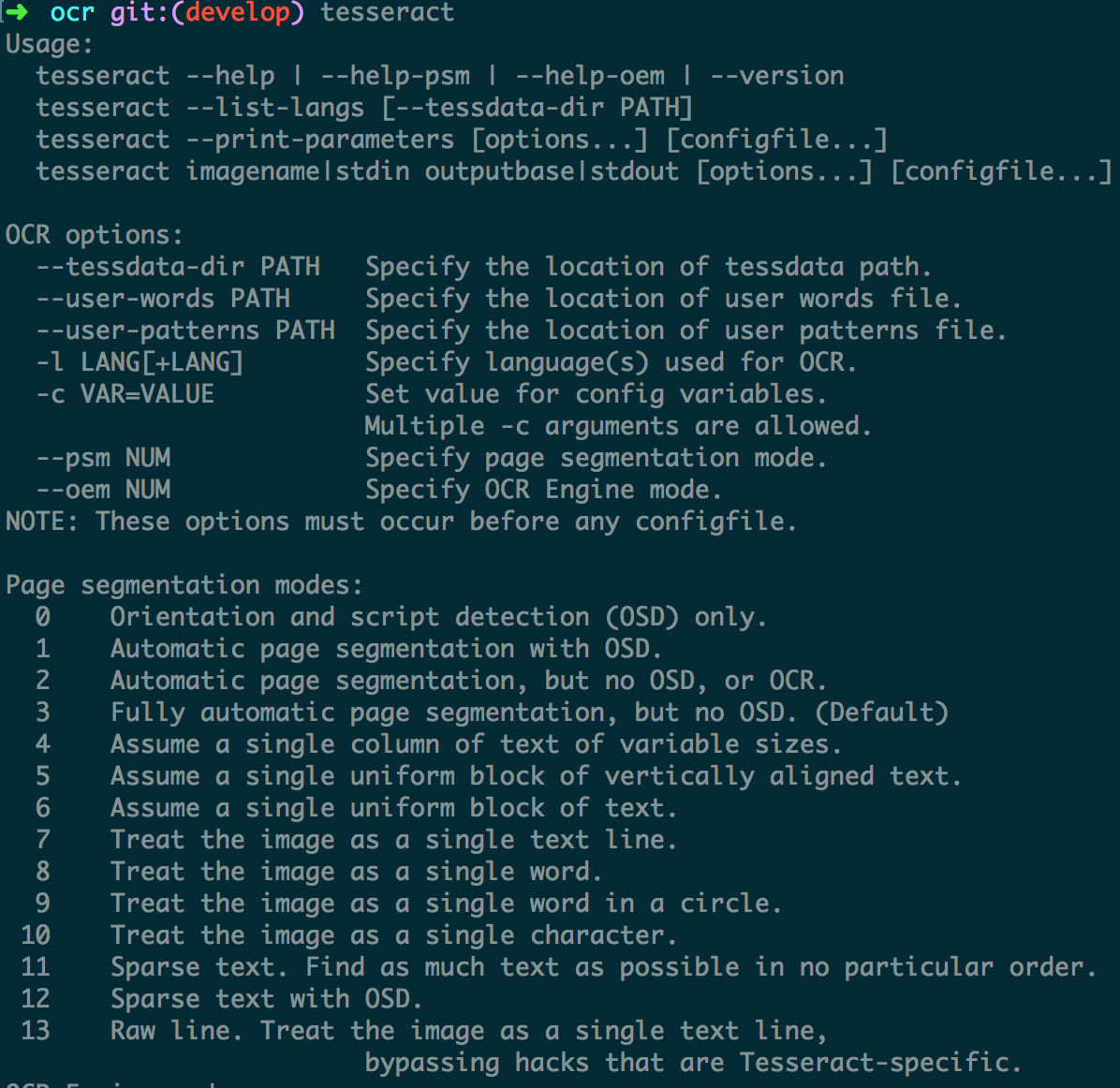
- 注意一下
-psm: 参数是指定文本模式,如果是单行文本可以指定为6,
-l: 参数指定识别使用的语言库,如eng,
查看当前可用语言库:
1
2
3
4
5➜ ocr git:(develop) tesseract --list-langs
List of available languages (10):
chi_sim # 简体中文库
live10 # 自己训练的语言库
eng # 英文库识别英文例子:
![例子图片]](/uploads/tesseract/tesseract-sample.png)
识别以后:
![识别后]](/uploads/tesseract/tesseract-recognize.png)识别中文:
![例子图片]](/uploads/tesseract/tesseract-ch.png)
![例子图片]](/uploads/tesseract/tesseract-ch-r.png)
- 准确率还是很高的,中文是识别出很多空格,可以自行处理一下
- 下次会分享如何手动训练自己的语言库,敬请期待